AzureMLへのデプロイ
ONNX Runtimeを使用して、高性能な質問応答モデルをAzureMLにデプロイする
Section titled “ONNX Runtimeを使用して、高性能な質問応答モデルをAzureMLにデプロイする”このチュートリアルでは、HuggingFaceのBERTモデルを取得し、ONNXに変換し、AzureMLを介してONNX RuntimeでONNXモデルをデプロイします。
以下のセクションでは、Stanford Question Answering Dataset (SQuAD) データセットでトレーニングされたHuggingFace BERTモデルを例として使用します。独自の質問応答モデルをトレーニングまたはファインチューニングすることもできます。
質問応答シナリオでは、質問とコンテキストと呼ばれるテキストの一部を取得し、コンテキストから取得したテキストの文字列である回答を生成します。このシナリオでは、質問とコンテキストをトークン化してエンコードし、入力をトランスフォーマーモデルに供給し、コンテキスト内で最も可能性の高い開始トークンと終了トークンを生成することによって回答を生成し、それらを単語にマッピングし直します。
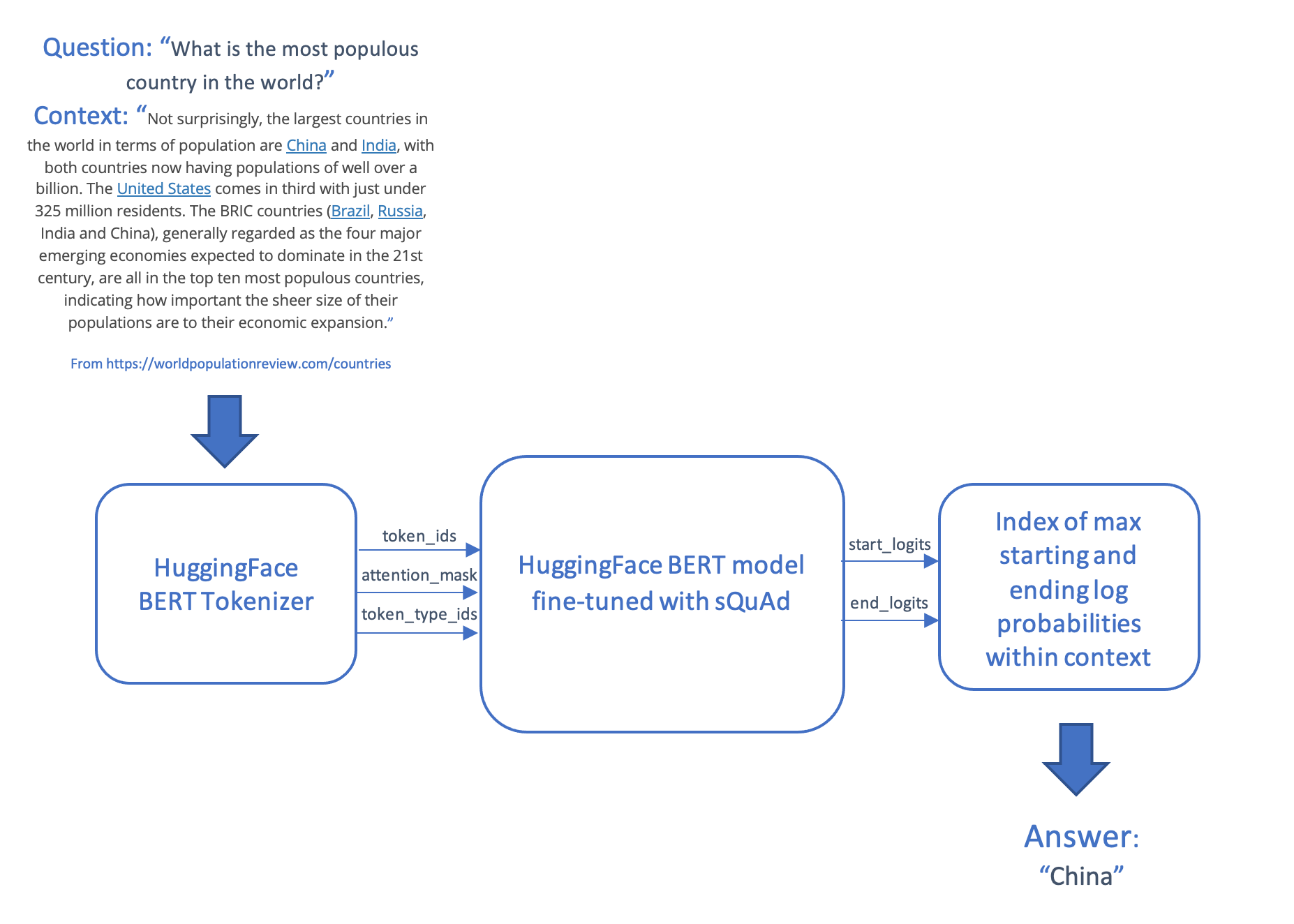
モデルとスコアリングコードは、オンラインエンドポイントを使用してAzureMLにデプロイされます。
このチュートリアルのソースコードはGitHubで公開されています。
AzureMLで実行するには、次のものが必要です。
- Azureサブスクリプション
- Azure Machine Learningワークスペース(まだない場合は、ワークスペースの作成についてAzureML構成ノートブックを参照してください)
- Azure Machine Learning SDK
- Azure CLIおよびAzure Machine learning CLI拡張機能(>バージョン2.2.2)
また、次のリソースも役立つ場合があります。
- Azure Machine Learningによって導入されたアーキテクチャと用語を理解する
- Azureポータルを使用すると、デプロイのステータスを追跡できます。
AzureMLサブスクリプションにアクセスできない場合は、このチュートリアルをローカルで実行できます。
依存関係を直接インストールするには、次を実行します
pip install torchpip install transformerspip install azureml azureml.corepip install onnxruntimepip install matplotlibconda環境からJupyterカーネルを作成するには、次を実行します。
conda install -c anaconda ipykernelpython -m ipykernel install --user --name=<kernel name>以下のデプロイ手順で使用されるAzureML CLI拡張機能をインストールします
az loginaz extension add --name ml# azure-cli-ml拡張機能がインストールされている場合は、az ml拡張機能と互換性がないため削除しますaz extension remove azure-cli-mlPyTorchモデルを取得してONNX形式に変換する
Section titled “PyTorchモデルを取得してONNX形式に変換する”以下のコードでは、HuggingFaceからSQUADデータセットで質問応答用にファインチューニングされたBERTモデルを取得します。
BERTモデルを最初から事前トレーニングしたい場合は、BERTモデルの事前トレーニングの手順に従ってください。また、独自のデータセットでモデルをファインチューニングしたい場合は、AzureML BERT Eval SquadまたはAzureML BERT Eval GLUEを参照してください。
モデルのエクスポート
Section titled “モデルのエクスポート”PyTorch ONNXエクスポーターを使用して、ONNX Runtimeで実行されるONNX形式のモデルを作成します。
import torchfrom transformers import BertForQuestionAnswering
model_name = "bert-large-uncased-whole-word-masking-finetuned-squad"model_path = "./" + model_name + ".onnx"model = BertForQuestionAnswering.from_pretrained(model_name)
# モデルを推論モードに設定します# モデルをエクスポートする前に、torch_model.eval()またはtorch_model.train(False)を呼び出して# モデルを推論モードにすることが重要です。これは、ドロップアウトやバッチ正規化などの演算子が# 推論モードとトレーニングモードで異なる動作をするためです。model.eval()
# モデルへのダミー入力を生成します。必要に応じて調整してくださいinputs = { 'input_ids': torch.randint(32, [1, 32], dtype=torch.long), # トークン化されたテキストの数値IDのリスト 'attention_mask': torch.ones([1, 32], dtype=torch.long), # 1のダミーリスト 'token_type_ids': torch.ones([1, 32], dtype=torch.long) # 1のダミーリスト }
symbolic_names = {0: 'batch_size', 1: 'max_seq_len'}torch.onnx.export(model, # 実行中のモデル (inputs['input_ids'], inputs['attention_mask'], inputs['token_type_ids']), # モデル入力(複数の入力の場合はタプル) model_path, # モデルの保存先(ファイルまたはファイルのようなオブジェクト) opset_version=11, # モデルをエクスポートするONNXバージョン do_constant_folding=True, # 最適化のために定数畳み込みを実行するかどうか input_names=['input_ids', 'input_mask', 'segment_ids'], # モデルの入力名 output_names=['start_logits', "end_logits"], # モデルの出力名 dynamic_axes={'input_ids': symbolic_names, 'input_mask' : symbolic_names, 'segment_ids' : symbolic_names, 'start_logits' : symbolic_names, 'end_logits': symbolic_names}) # 可変長の軸ONNX RuntimeでONNXモデルを実行する
Section titled “ONNX RuntimeでONNXモデルを実行する”次のコードは、ONNX RuntimeでONNXモデルを実行します。Azure Machine Learningにデプロイする前に、ローカルでテストできます。
init()関数は起動時に呼び出され、トークナイザーとONNX Runtimeセッションの作成などの1回限りの操作を実行します。
run()関数は、Azure MLエンドポイントを使用してモデルを実行するときに呼び出されます。必要なpreprocess()およびpostprocess()ステップを追加します。
ローカルでのテストと比較のために、PyTorchモデルを実行することもできます。
import osimport loggingimport jsonimport numpy as npimport onnxruntimeimport transformersimport torch
# 前処理関数は、質問とコンテキストを受け取り、モデルへのテンソル入力を生成します。# - input_ids: 質問内の単語を整数としてエンコードしたもの# - attention_mask: このモデルでは使用されません# - token_type_ids: 質問の単語とコンテキストの単語を区別する0と1のリスト# この関数は、質問とコンテキストに含まれる単語も返し、回答をフレーズにデコードできるようにします。def preprocess(question, context): encoded_input = tokenizer(question, context) tokens = tokenizer.convert_ids_to_tokens(encoded_input.input_ids) return (encoded_input.input_ids, encoded_input.attention_mask, encoded_input.token_type_ids, tokens)
# 後処理関数は、開始と終了の対数確率のリストを、質問とコンテキストからのテキストトークンを使用して# テキストの回答にマッピングします。def postprocess(tokens, start, end): results = {} answer_start = np.argmax(start) answer_end = np.argmax(end) if answer_end >= answer_start: answer = tokens[answer_start] for i in range(answer_start+1, answer_end+1): if tokens[i][0:2] == "##": answer += tokens[i][2:] else: answer += " " + tokens[i] results['answer'] = answer.capitalize() else: results['error'] = "この質問に対する答えを見つけることができません。別の質問をしてください。" return results
# 予測のための1回限りの初期化を実行します。initコードは、エンドポイントのセットアップ時に1回実行されます。def init(): global tokenizer, session, model
model_name = "bert-large-uncased-whole-word-masking-finetuned-squad" model = transformers.BertForQuestionAnswering.from_pretrained(model_name)
# AZUREML_MODEL_DIRを使用して、デプロイされたモデルを取得します。複数のモデルがデプロイされている場合は、 # model_path = os.path.join(os.getenv('AZUREML_MODEL_DIR'), '$MODEL_NAME/$VERSION/$MODEL_FILE_NAME') model_dir = os.getenv('AZUREML_MODEL_DIR') if model_dir == None: model_dir = "./" model_path = os.path.join(model_dir, model_name + ".onnx")
# トークナイザーを作成します tokenizer = transformers.BertTokenizer.from_pretrained(model_name)
# ONNXモデルを実行するためのONNX Runtimeセッションを作成します session = onnxruntime.InferenceSession(model_path, providers=["CPUExecutionProvider"])
# 機能とパフォーマンスの比較のために、PyTorchモデルを実行しますdef run_pytorch(raw_data): inputs = json.loads(raw_data)
model.eval()
logging.info("Question:", inputs["question"]) logging.info("Context: ", inputs["context"])
input_ids, input_mask, segment_ids, tokens = preprocess(inputs["question"], inputs["context"]) model_outputs = model(torch.tensor([input_ids]), token_type_ids=torch.tensor([segment_ids])) return postprocess(tokens, model_outputs.start_logits.detach().numpy(), model_outputs.end_logits.detach().numpy())
# ONNX RuntimeでONNXモデルを実行しますdef run(raw_data): logging.info("Request received") inputs = json.loads(raw_data) logging.info(inputs)
# 質問とコンテキストをトークン化されたIDに前処理します input_ids, input_mask, segment_ids, tokens = preprocess(inputs["question"], inputs["context"]) logging.info("Running inference")
# ONNX Runtimeの入力をフォーマットします model_inputs = { 'input_ids': [input_ids], 'input_mask': [input_mask], 'segment_ids': [segment_ids] }
outputs = session.run(['start_logits', 'end_logits'], model_inputs) logging.info("Post-processing")
# モデルの出力を回答に後処理します(質問に回答できなかった場合はエラー) results = postprocess(tokens, outputs[0], outputs[1]) logging.info(results) return results
if __name__ == '__main__': init()
input = "{\"question\": \"What is Dolly Parton's middle name?\", \"context\": \"Dolly Rebecca Parton is an American singer-songwriter\"}"
run_pytorch(input) print(run(input))AzureMLを介してONNX Runtimeでモデルをデプロイする
Section titled “AzureMLを介してONNX Runtimeでモデルをデプロイする”ONNXモデルとONNX Runtimeで実行するコードができたので、Azure MLを使用してデプロイできます。
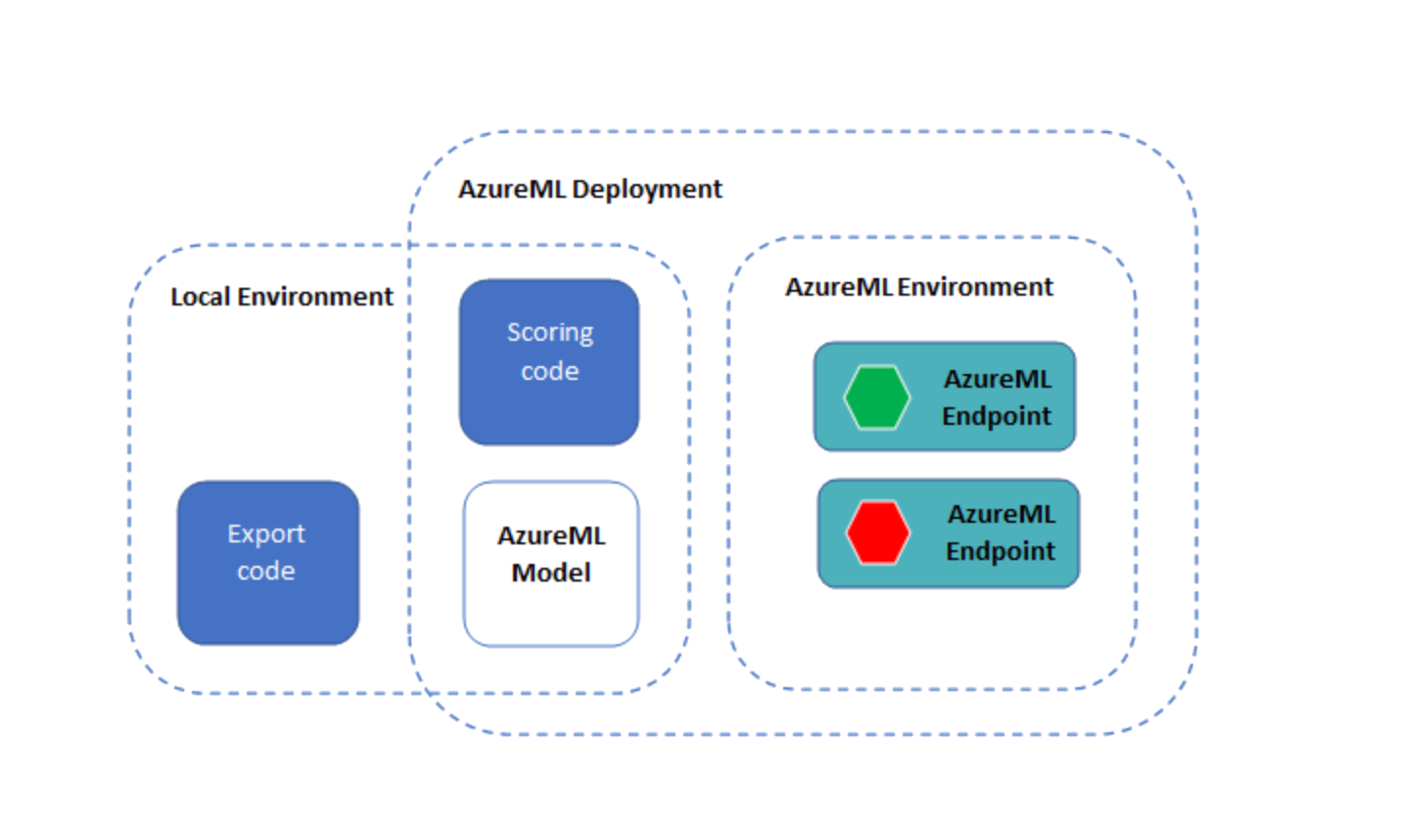
環境を確認する
Section titled “環境を確認する”import azureml.coreimport onnxruntimeimport torchimport transformers
print("Transformers version: ", transformers.__version__)torch_version = torch.__version__print("Torch (ONNX exporter) version: ", torch_version)print("Azure SDK version:", azureml.core.VERSION)print("ONNX Runtime version: ", onnxruntime.__version__)Azure MLワークスペースをロードする
Section titled “Azure MLワークスペースをロードする”まず、構成ノートブックで以前に作成した既存のワークスペースからワークスペースオブジェクトをインスタンス化します。
次のコードは、ノートブックと同じディレクトリ、または.azuremlというサブディレクトリに、サブスクリプション情報を含むconfig.jsonファイルがあることを前提としていることに注意してください。Workspace.get()メソッドを使用して、ワークスペース名、サブスクリプション名、リソースグループを明示的に指定することもできます。
import osfrom azureml.core import Workspace
ws = Workspace.from_config()print(ws.name, ws.location, ws.resource_group, ws.subscription_id, sep = '\n')Azure MLにモデルを登録する
Section titled “Azure MLにモデルを登録する”次に、モデルをアップロードしてワークスペースに登録します。
from azureml.core.model import Model
model = Model.register(model_path = model_path, # ワークスペース内の登録済みモデルの名前。 model_name = model_name, # アップロードしてモデルとして登録するローカルONNXモデル model_framework=Model.Framework.ONNX , # モデルの作成に使用されたフレームワーク。 model_framework_version=torch_version, # モデルの作成に使用されたONNXのバージョン。 tags = {"onnx": "demo"}, description = "HuggingFace BERT model fine-tuned with SQuAd and exported from PyTorch", workspace = ws)登録済みモデルを表示する
Section titled “登録済みモデルを表示する”このワークスペースに登録したすべてのモデルを一覧表示できます。
models = ws.modelsfor name, m in models.items(): print("Name:", name,"\tVersion:", m.version, "\tDescription:", m.description, m.tags)
# # ワークスペースからモデルを削除したい場合# model_to_delete = Model(ws, name)# model_to_delete.delete()モデルとスコアリングコードをAzureMLエンドポイントとしてデプロイする
Section titled “モデルとスコアリングコードをAzureMLエンドポイントとしてデプロイする”注:Python SDKのエンドポイントインターフェイスはまだ公開されていないため、このセクションではAzure ML CLIを使用します。
ymlフォルダには3つのYMLファイルがあります。
env.yml:エンドポイントの実行環境が生成されるconda環境仕様endpoint.yml:エンドポイントの名前と認証方法のみを含むエンドポイント仕様deployment.yml:スコアリングコード、モデル、環境の仕様を含むデプロイ仕様。エンドポイントごとに複数のデプロイを作成し、デプロイに異なる量のトラフィックをルーティングできます。この例では、1つのデプロイのみを作成します。
デプロイには最大15分かかる場合があります。また、ノートブックのあるディレクトリ内のすべてのファイルは、エンドポイントの基盤となるDockerコンテナにアップロードされることに注意してください。これには、ONNXモデルのローカルコピーも含まれます(前の手順でAzureMLにすでにデプロイされています)。デプロイ時間を短縮するには、エンドポイントを作成する前に、大きなファイルのローカルコピーを削除してください。
az ml online-endpoint create --name question-answer-ort --file yml/endpoint.yml --subscription {ws.subscription_id} --resource-group {ws.resource_group} --workspace-name {ws.name}az ml online-deployment create --endpoint-name question-answer-ort --name blue --file yml/deployment.yml --all-traffic --subscription {ws.subscription_id} --resource-group {ws.resource_group} --workspace-name {ws.name}デプロイされたエンドポイントをテストする
Section titled “デプロイされたエンドポイントをテストする”次のコマンドは、デプロイされた質問応答モデルを実行します。test-data.jsonファイルにテスト用の質問があります。このファイルを編集して、独自の質問とコンテキストを使用できます。
az ml online-endpoint invoke --name question-answer-ort --request-file test-data.json --subscription {ws.subscription_id} --resource-group {ws.resource_group} --workspace-name {ws.name}ここまで到達した場合、ONNXモデルを使用して質問に回答する動作中のエンドポイントをデプロイしました。
独自の質問とコンテキストを提供して、質問に回答できます!
Azureリソースのクリーンアップ
Section titled “Azureリソースのクリーンアップ”次のコマンドは、デプロイしたAzureMLエンドポイントを削除します。AzureMLワークスペース、コンピューティング、登録済みモデルもクリーンアップしたい場合があります。
az ml online-endpoint delete --name question-answer-ort --yes --subscription {ws.subscription_id} --resource-group {ws.resource_group} --workspace-name {ws.name}