実行プロバイダー
ONNX Runtimeは、拡張可能な実行プロバイダー(EP)フレームワークを通じて異なるハードウェア加速ライブラリと連携し、ハードウェアプラットフォーム上でONNXモデルを最適に実行します。このインターフェースにより、APアプリケーション開発者は、クラウドとエッジの異なる環境でONNXモデルをデプロイし、プラットフォームの計算能力を活用して実行を最適化する柔軟性を得ることができます。
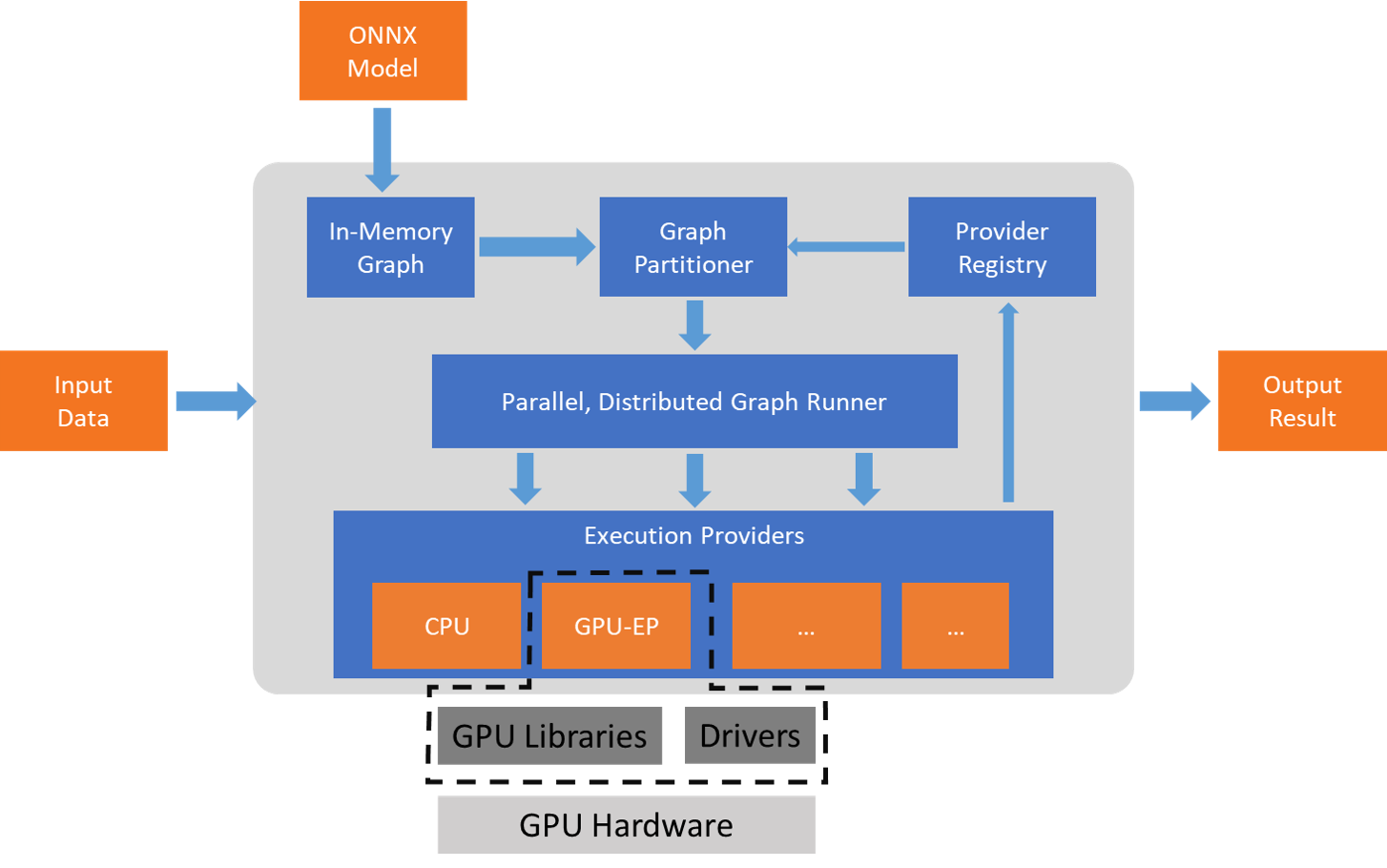
ONNX Runtimeは、GetCapability()インターフェースを使用して実行プロバイダーと連携し、サポートされているハードウェアでEPライブラリによる実行のために特定のノードまたはサブグラフを割り当てます。実行環境にプリインストールされたEPライブラリが、ハードウェア上でONNXサブグラフを処理・実行します。このアーキテクチャは、CPU、GPU、FPGA、または専用NPUなどのハードウェアプラットフォーム間でディープニューラルネットワークの実行を最適化するために不可欠なハードウェア固有ライブラリの詳細を抽象化します。
ONNX Runtimeは現在、多くの異なる実行プロバイダーをサポートしています。一部のEPは本番サービスで稼働中ですが、他のものは開発者が異なるオプションを使用してアプリケーションを開発・カスタマイズできるようにプレビューでリリースされています。
サポートされている実行プロバイダーの概要
Section titled “サポートされている実行プロバイダーの概要”| CPU | GPU | IoT/Edge/Mobile | その他 | |
|---|---|---|---|---|
| デフォルトCPU | NVIDIA CUDA | Intel OpenVINO | Rockchip NPU (プレビュー) | |
| Intel DNNL | NVIDIA TensorRT | Arm Compute Library (プレビュー) | Xilinx Vitis-AI (プレビュー) | |
| TVM (プレビュー) | DirectML | Android Neural Networks API | Huawei CANN (プレビュー) | |
| Intel OpenVINO | AMD MIGraphX | Arm NN (プレビュー) | AZURE (プレビュー) | |
| XNNPACK | Intel OpenVINO | CoreML (プレビュー) | ||
| AMD ROCm | TVM (プレビュー) | |||
| TVM (プレビュー) | Qualcomm QNN | |||
| XNNPACK |
実行プロバイダーの追加
Section titled “実行プロバイダーの追加”専用HW加速ソリューションの開発者は、ONNX Runtimeと統合して自分のスタック上でONNXモデルを実行できます。ONNX RuntimeとインターフェースするためのEPを作成するには、まずEPの一意の名前を特定する必要があります。詳細な手順については、新しい実行プロバイダーの追加を参照してください。
EPを含むONNX Runtimeパッケージのビルド
Section titled “EPを含むONNX Runtimeパッケージのビルド”ONNX Runtimeパッケージは、デフォルトのCPU実行プロバイダーと組み合わせて、EPの任意の組み合わせでビルドできます。注意:複数のEPが同じONNX Runtimeパッケージに組み合わされる場合、すべての依存ライブラリが実行環境に存在する必要があります。異なるEPでONNX Runtimeパッケージを作成する手順はこちらに文書化されています。
実行プロバイダー用API
Section titled “実行プロバイダー用API”すべてのEPで同じONNX Runtime APIが使用されます。これにより、アプリケーションが異なるHW加速プラットフォームで実行するための一貫したインターフェースが提供されます。EPオプションを設定するAPIは、Python、C/C++/C#、Java、node.jsで利用できます。
注意:すべての言語バインディング間でAPIサポートの同等性を得るためにAPIサポートを更新中であり、ここで詳細を更新します。
`get_providers`: 登録された実行プロバイダーのリストを返します。`get_provider_options`: 登録された実行プロバイダーの設定を返します。`set_providers`: 指定された実行プロバイダーのリストを登録します。基盤となるセッションが再作成されます。 プロバイダーのリストは優先度順に並べられます。例:['CUDAExecutionProvider', 'CPUExecutionProvider'] は、可能であればCUDAExecutionProviderを使用してノードを実行し、そうでなければCPUExecutionProviderを使用して実行することを意味します。実行プロバイダーの使用
Section titled “実行プロバイダーの使用”import onnxruntime as rt
# 実行プロバイダーの優先順位を定義# CPU実行プロバイダーよりもCUDA実行プロバイダーを優先EP_list = ['CUDAExecutionProvider', 'CPUExecutionProvider']
# model.onnxを初期化sess = rt.InferenceSession("model.onnx", providers=EP_list)
# :class:`onnxruntime.NodeArg`のリストとして出力メタデータを取得output_name = sess.get_outputs()[0].name
# :class:`onnxruntime.NodeArg`のリストとして入力メタデータを取得input_name = sess.get_inputs()[0].name
# image_dataをモデルへの入力として使用した推論実行detections = sess.run([output_name], {input_name: image_data})[0]
print("Output shape:", detections.shape)
# 推論ポイントをマークするために画像を処理image = post.image_postprocess(original_image, input_size, detections)image = Image.fromarray(image)image.save("kite-with-objects.jpg")
# EP優先度をCPUExecutionProviderのみに更新sess.set_providers(['CPUExecutionProvider'])
cpu_detection = sess.run(...)